


Hot Topics #29 (Jul 8, 2024)
Discrete-Continuous diffusion models, diffusion-based priors, Dirichlet flow matching, and more.

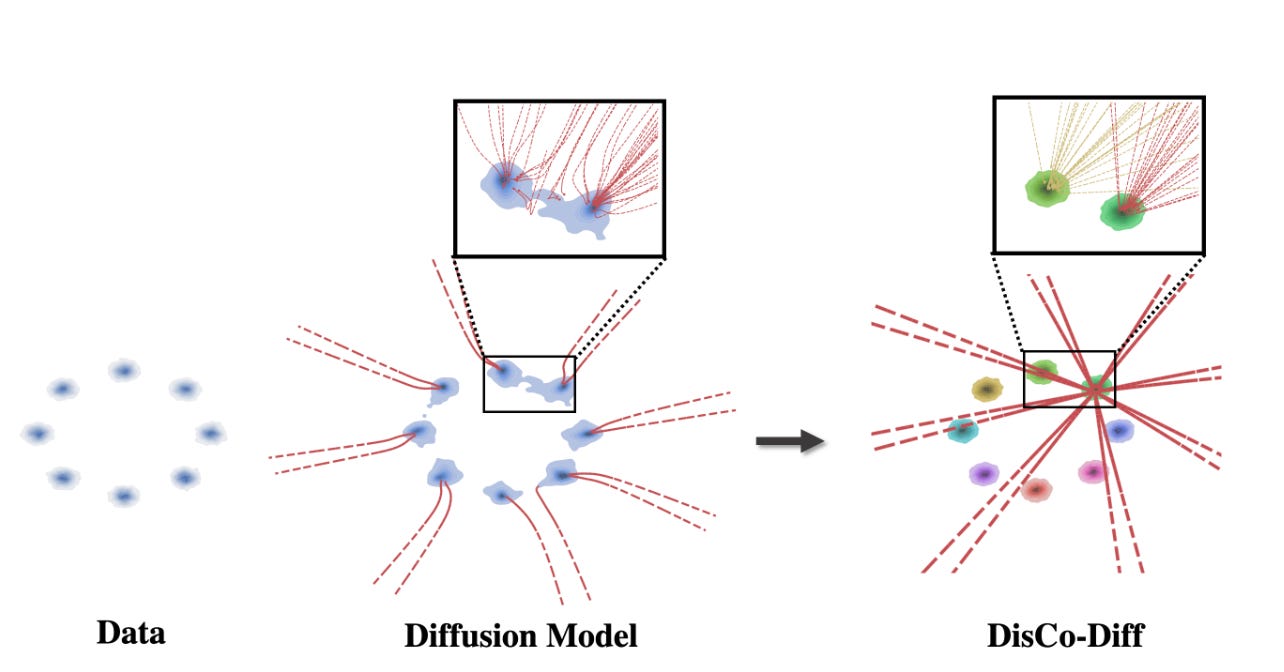

DisCo-Diff: Enhancing Continuous Diffusion Models with Discrete Latents: Xu et al.: July 24
Abstract: Diffusion models (DMs) have revolutionized generative learning. They utilize a diffusion process to encode data into a simple Gaussian distribution. However, encoding a complex, potentially multimodal data distribution into a single continuous Gaussian distribution arguably represents an unnecessarily challenging learning problem. We propose Discrete-Continuous Latent Variable Diffusion Models (DisCo-Diff) to simplify this task by introducing complementary discrete latent variables. We augment DMs with learnable discrete latents, inferred with an encoder, and train DM and encoder end-to-end. DisCo-Diff does not rely on pre-trained networks, making the framework universally applicable. The discrete latents significantly simplify learning the DM's complex noise-to-data mapping by reducing the curvature of the DM's generative ODE. An additional autoregressive transformer models the distribution of the discrete latents, a simple step because DisCo-Diff requires only few discrete variables with small codebooks. We validate DisCo-Diff on toy data, several image synthesis tasks as well as molecular docking, and find that introducing discrete latents consistently improves model performance. For example, DisCo-Diff achieves state-of-the-art FID scores on class-conditioned ImageNet-64/128 datasets with ODE sampler.
Solving Inverse Problems in Protein Space Using Diffusion-Based Priors: Levy et al.: June 6, 2024
Abstract: The interaction of a protein with its environment can be understood and controlled via its 3D structure. Experimental methods for protein structure determination, such as X-ray crystallography or cryogenic electron microscopy, shed light on biological processes but introduce challenging inverse problems. Learning-based approaches have emerged as accurate and efficient methods to solve these inverse problems for 3D structure determination, but are specialized for a predefined type of measurement. Here, we introduce a versatile framework to turn raw biophysical measurements of varying types into 3D atomic models. Our method combines a physics-based forward model of the measurement process with a pretrained generative model providing a task-agnostic, data-driven prior. Our method outperforms posterior sampling baselines on both linear and non-linear inverse problems. In particular, it is the first diffusion-based method for refining atomic models from cryo-EM density maps.
Dirichlet Flow Matching with Applications to DNA Sequence Design: Stark et al.: Feb 8, 2024
Abstract: Discrete diffusion or flow models could enable faster and more controllable sequence generation than autoregressive models. We show that naïve linear flow matching on the simplex is insufficient toward this goal since it suffers from discontinuities in the training target and further pathologies. To overcome this, we develop Dirichlet flow matching on the simplex based on mixtures of Dirichlet distributions as probability paths. In this framework, we derive a connection between the mixtures' scores and the flow's vector field that allows for classifier and classifier-free guidance. Further, we provide distilled Dirichlet flow matching, which enables one-step sequence generation with minimal performance hits, resulting in O(L) speedups compared to autoregressive models. On complex DNA sequence generation tasks, we demonstrate superior performance compared to all baselines in distributional metrics and in achieving desired design targets for generated sequences. Finally, we show that our classifier-free guidance approach improves unconditional generation and is effective for generating DNA that satisfies design targets. Code is available at this https URL.
RNAFlow: RNA Structure & Sequence Design via Inverse Folding-Based Flow Matching: Nori & Jin: May 29, 2024
Abstract: The growing significance of RNA engineering in diverse biological applications has spurred interest in developing AI methods for structure-based RNA design. While diffusion models have excelled in protein design, adapting them for RNA presents new challenges due to RNA's conformational flexibility and the computational cost of fine-tuning large structure prediction models. To this end, we propose RNAFlow, a flow matching model for protein-conditioned RNA sequence-structure design. Its denoising network integrates an RNA inverse folding model and a pre-trained RosettaFold2NA network for generation of RNA sequences and structures. The integration of inverse folding in the structure denoising process allows us to simplify training by fixing the structure prediction network. We further enhance the inverse folding model by conditioning it on inferred conformational ensembles to model dynamic RNA conformations. Evaluation on protein-conditioned RNA structure and sequence generation tasks demonstrates RNAFlow's advantage over existing RNA design methods.
Better & Faster Large Language Models via Multi-token Prediction: Gloeckle et al.: April 30, 2024
Abstract: Large language models such as GPT and Llama are trained with a next-token prediction loss. In this work, we suggest that training language models to predict multiple future tokens at once results in higher sample efficiency. More specifically, at each position in the training corpus, we ask the model to predict the following n tokens using n independent output heads, operating on top of a shared model trunk. Considering multi-token prediction as an auxiliary training task, we measure improved downstream capabilities with no overhead in training time for both code and natural language models. The method is increasingly useful for larger model sizes, and keeps its appeal when training for multiple epochs. Gains are especially pronounced on generative benchmarks like coding, where our models consistently outperform strong baselines by several percentage points. Our 13B parameter models solves 12 % more problems on HumanEval and 17 % more on MBPP than comparable next-token models. Experiments on small algorithmic tasks demonstrate that multi-token prediction is favorable for the development of induction heads and algorithmic reasoning capabilities. As an additional benefit, models trained with 4-token prediction are up to 3 times faster at inference, even with large batch sizes.

Queueing blog from encore.dev: Provides cool, intuitive, interactive visualizations of different types of queues and how they work.
Mojo language: Mojo combines the usability of Python with the performance of C, unlocking unparalleled programmability of AI hardware and extensibility of AI models.