


Hot Topics #16 (Jan. 29, 2023)
Learning-rate-free learning, generalization in supervised models, molecular dynamics cell simulation,and more.


Learning-Rate-Free Learning by D-Adaptation: Defazio & Mishchenko; Jan. 18, 2023
Abstract: The speed of gradient descent for convex Lipschitz functions is highly dependent on the choice of learning rate. Setting the learning rate to achieve the optimal convergence rate requires knowing the distance D from the initial point to the solution set. In this work, we describe a single-loop method, with no back-tracking or line searches, which does not require knowledge of D yet asymptotically achieves the optimal rate of convergence for the complexity class of convex Lipschitz functions. Our approach is the first parameter-free method for this class without additional multiplicative log factors in the convergence rate. We present extensive experiments for SGD and Adam variants of our method, where the method automatically matches hand-tuned learning rates across more than a dozen diverse machine learning problems, including large-scale vision and language problems. Our method is practical, efficient and requires no additional function value or gradient evaluations each step. An open-source implementation is available (this https URL).
No Reason for No Supervision: Improved Generalization in Supervised Models: Anonymous authors (under review); Nov. 16, 2022
Abstract: We consider the problem of training a deep neural network on a given classification task, e.g., ImageNet-1K (IN1K), so that it excels at both the training task as well as at other (future) transfer tasks. These two seemingly contradictory properties impose a trade-off between improving the model’s generalization while maintaining its performance on the original task. Models trained with self-supervised learning tend to generalize better than their supervised counterparts for transfer learning; yet, they still lag behind supervised models on IN1K. In this paper, we propose a supervised learning setup that leverages the best of both worlds. We extensively analyse supervised training using multi-scale crops for data augmentation and an expendable projector head, and reveal that the design of the projector allows us to control the trade-off between performance on the training task and transferability. We further replace the last layer of class weights with class prototypes computed on the fly using a memory bank and derive two models: t-ReX that achieves a new state of the art for transfer learning and outperforms top methods such as DINO and PAWS on IN1K, and t-ReX* that matches the highly optimized RSB-A1 model on IN1K while performing better on transfer tasks. Finally, we perform several analyses of the features and class weights to present insights on how each component of our setup affects the training and learned representations.
Discovering Policies with DOMiNO: Diversity Optimization Maintaining Near Optimality: Zahavy et al.; May 26, 2022
Abstract: Finding different solutions to the same problem is a key aspect of intelligence associated with creativity and adaptation to novel situations. In reinforcement learning, a set of diverse policies can be useful for exploration, transfer, hierarchy, and robustness. We propose DOMiNO, a method for Diversity Optimization Maintaining Near Optimality. We formalize the problem as a Constrained Markov Decision Process where the objective is to find diverse policies, measured by the distance between the state occupancies of the policies in the set, while remaining near-optimal with respect to the extrinsic reward. We demonstrate that the method can discover diverse and meaningful behaviors in various domains, such as different locomotion patterns in the DeepMind Control Suite. We perform extensive analysis of our approach, compare it with other multi-objective baselines, demonstrate that we can control both the quality and the diversity of the set via interpretable hyperparameters, and show that the discovered set is robust to perturbations.
Progress measures for grokking via mechanistic interpretability: Nanda et al.; Jan. 12, 2023
Abstract: Neural networks often exhibit emergent behavior, where qualitatively new capabilities arise from scaling up the amount of parameters, training data, or training steps. One approach to understanding emergence is to find continuous \textit{progress measures} that underlie the seemingly discontinuous qualitative changes. We argue that progress measures can be found via mechanistic interpretability: reverse-engineering learned behaviors into their individual components. As a case study, we investigate the recently-discovered phenomenon of ``grokking'' exhibited by small transformers trained on modular addition tasks. We fully reverse engineer the algorithm learned by these networks, which uses discrete Fourier transforms and trigonometric identities to convert addition to rotation about a circle. We confirm the algorithm by analyzing the activations and weights and by performing ablations in Fourier space. Based on this understanding, we define progress measures that allow us to study the dynamics of training and split training into three continuous phases: memorization, circuit formation, and cleanup. Our results show that grokking, rather than being a sudden shift, arises from the gradual amplification of structured mechanisms encoded in the weights, followed by the later removal of memorizing components.
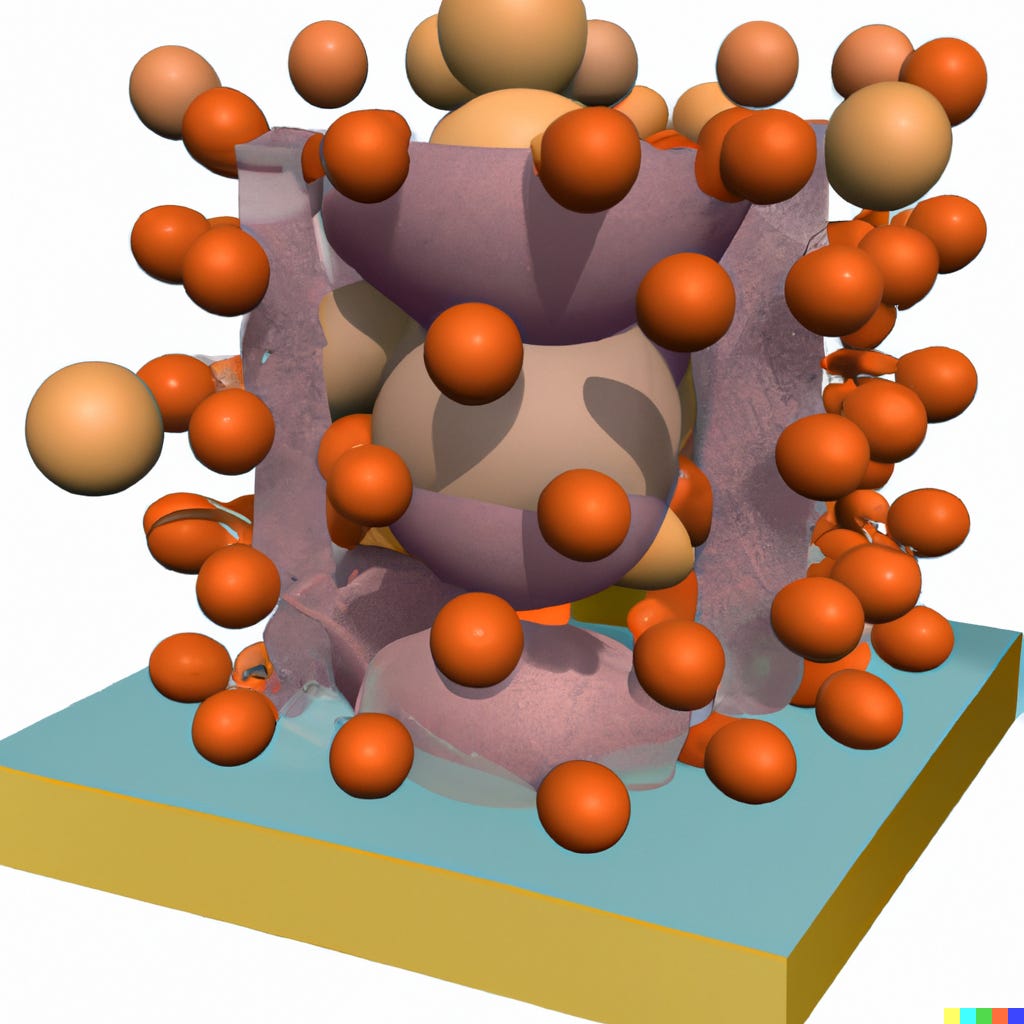
Molecular dynamics simulation of an entire cell: Stevens et al.; Jan. 18, 2023
Abstract: The ultimate microscope, directed at a cell, would reveal the dynamics of all the cell’s components with atomic resolution. In contrast to their real-world counterparts, computational microscopes are currently on the brink of meeting this challenge. In this perspective, we show how an integrative approach can be employed to model an entire cell, the minimal cell, JCVI-syn3A, at full complexity. This step opens the way to interrogate the cell’s spatio-temporal evolution with molecular dynamics simulations, an approach that can be extended to other cell types in the near future.

RL4LMs: A modular RL library to fine-tune language models to human preferences.
Deep Learning Tuning Playbook: This document is for engineers and researchers (both individuals and teams) interested in maximizing the performance of deep learning models. We assume basic knowledge of machine learning and deep learning concepts.
